Moment Matching for
Multi-Source Domain Adaptation
Our paper is accepted by ICCV 2019 as an Oral Presentation!
Abstract
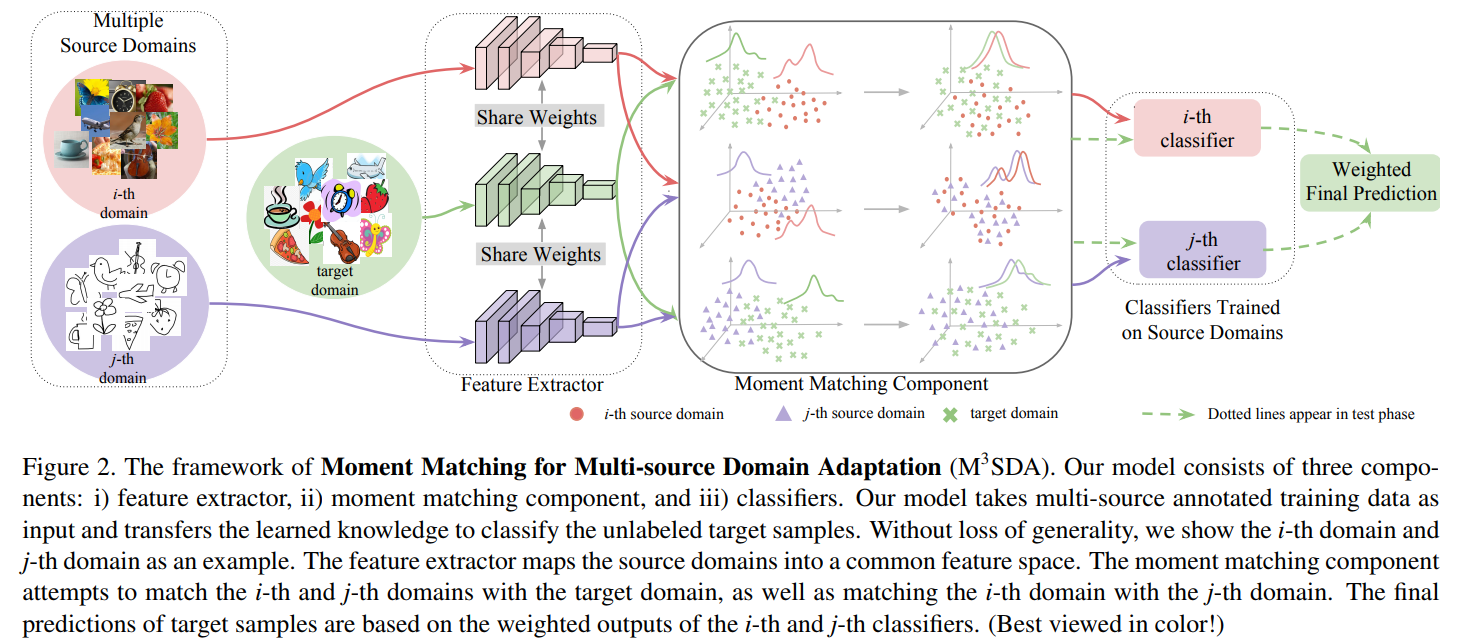
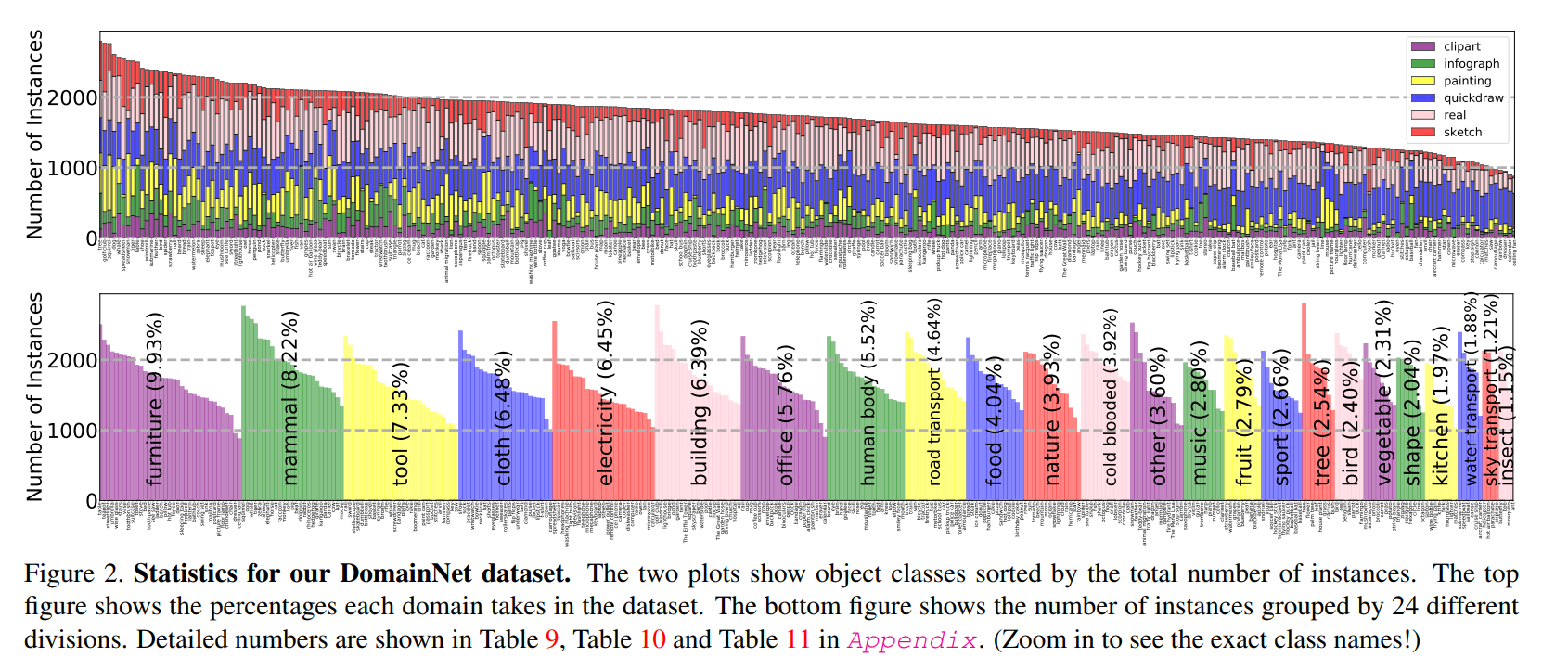
Conventional unsupervised domain adaptation (UDA) assumes that training data are sampled from a single domain. This neglects the more practical scenario where training data are collected from multiple sources, requiring multi-source domain adaptation. We make three major contributions towards addressing this problem. First, we propose a new deep learning approach, Moment Matching for Multi-Source Domain Adaptation (M3SDA), which aims to transfer knowledge learned from multiple labeled source domains to an unlabeled target domain by dynamically aligning moments of their feature distributions. Second, we provide a sound theoretical analysis of moment-related error bounds for multi-source domain adaptation. Third, we collect and annotate by far the largest UDA dataset with six distinct domains and approximately 0.6 million images distributed among 345 categories, addressing the gap in data availability for multi-source UDA research. Extensive experiments are performed to demonstrate the effectiveness of our proposed model, which outperforms existing state-ofthe-art methods by a large margin.

Download (cleaned version, recommended)
Special Thanks to Guoliang Kang for pointing out the image duplications in our dataset.
| Clipart | Infograph | Painting | Quickdraw | Real | Sketch | |
|---|---|---|---|---|---|---|
| Data | clipart.zip(1.3G) | infograph.zip(4.0G) | painting.zip(3.7G) | quickdraw.zip(439M) | real.zip(5.6G) | sketch.zip(2.5G) |
| Train | clipart_train.txt | infograph_train.txt | painting_train.txt | quickdraw_train.txt | real_train.txt | sketch_train.txt |
| Test | clipart_test.txt | infograph_test.txt | painting_test.txt | quickdraw_test.txt | real_test.txt | sketch_test.txt |
| #Original | 48,837 | 53,201 | 75,759 | 172,500 | 175,327 | 70,386 |
| #Cleaned | 48,129 | 51,605 | 72,266 | 172,500 | 172,947 | 69,128 |
| Removed | 1.4% | 2.9% | 4.6% | 0 | 1.4% | 1.8% |
Download
| Clipart | Infograph | Painting | Quickdraw | Real | Sketch | |
|---|---|---|---|---|---|---|
| Data | clipart.zip(1.3G) | infograph.zip(4.0G) | painting.zip(3.7G) | quickdraw.zip(439M) | real.zip(5.6G) | sketch.zip(2.5G) |
| Train | clipart_train.txt | infograph_train.txt | painting_train.txt | quickdraw_train.txt | real_train.txt | sketch_train.txt |
| Test | clipart_test.txt | infograph_test.txt | painting_test.txt | quickdraw_test.txt | real_test.txt | sketch_test.txt |
VisDA 2019 Challenge Download
| Clipart | Infograph | Painting | Quickdraw | Real | Sketch | |
|---|---|---|---|---|---|---|
| Data | clipart.zip(1.3G) | infograph.zip(4.0G) | painting.zip(3.7G) | quickdraw.zip(439M) | real.zip(5.6G) | sketch.zip(2.5G) |
| Train | clipart_train.txt | infograph_train.txt | painting_train.txt | quickdraw_train.txt | real_train.txt | sketch_train.txt |
| Test | clipart_test.txt | infograph_test.txt | painting_test.txt | quickdraw_test.txt | real_test.txt | sketch_test.txt |
- We have released the training/testing images of clipart and painting subset now!
- For Infograph, Quickdraw, Real, Sketch domains, the train/test images are structured in folders as {domain}/{cateogory}/{object_id}.jpg (or .png)
- For clipart and painting domains, the train/test images are structured as {domain}/{train/test}/{trunk_ID}/{MD5}.jpg
- To prepare for the submission, please output the predictions to a "result.txt" file, with one prediciton ranging from 0 to 344 per line (37706 lines for 37706 test samples). The order of the testing images is listed in submission_list.txt.
Reference
If you find this useful in your work please consider citing:
@inproceedings{peng2019moment,
title={Moment matching for multi-source domain adaptation},
author={Peng, Xingchao and Bai, Qinxun and Xia, Xide and Huang, Zijun and Saenko, Kate and Wang, Bo},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
pages={1406--1415},
year={2019}
}
Fair Use Notice
This dataset contains some copyrighted material whose use has not been specifically authorized by the copyright owners. In an effort to advance scientific research, we make this material available for academic research. We believe this constitutes a fair use of any such copyrighted material as provided for in section 107 of the US Copyright Law. In accordance with Title 17 U.S.C. Section 107, the material on this site is distributed without profit for non-commercial research and educational purposes. For more information on fair use please click here. If you wish to use copyrighted material on this site or in our dataset for purposes of your own that go beyond non-commercial research and academic purposes, you must obtain permission directly from the copyright owner. (adapted from Christopher Thomas)