Multi-Critic Actor Learning: Teaching RL Policies to Act with Style
Abstract
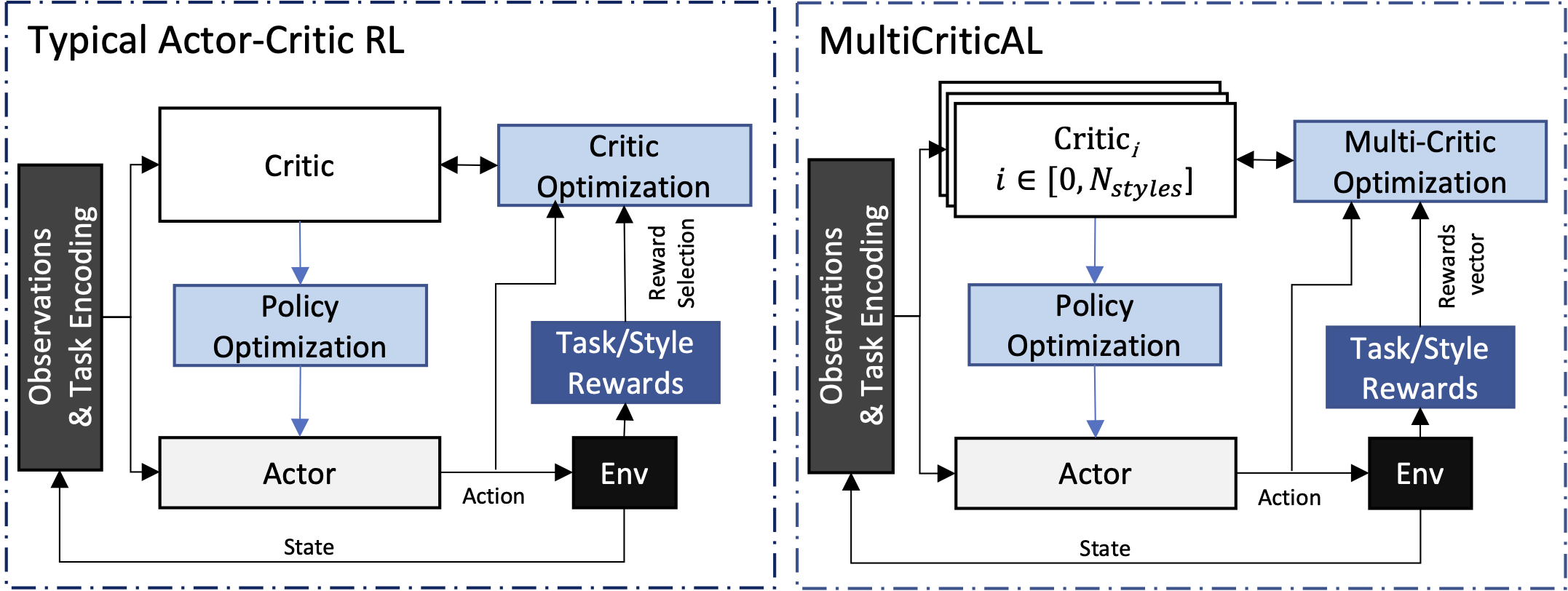
Using a single value function (critic) shared over multiple tasks in Actor-Critic multi-task reinforcement learning (MTRL) can result in negative interference between tasks, which can compromise learning performance. Multi-Critic Actor Learning (MultiCriticAL) proposes instead maintaining separate critics for each task being trained, while training a single multi-task actor. Explicitly distinguishing between tasks also eliminates the need for critics to learn to do so and mitigates interference between task-value estimates. MultiCriticAL is tested in the context of multi-style learning, a special case of MTRL where agents are trained to behave with different distinct behavior styles, and yields up to 56% performance gains over the single-critic baselines and even successfully learns behavior styles in cases where single-critic approaches may simply fail to learn. To simulate a real-world use-case, MultiCriticAL is tested on an experimental build of EA’s UFC game, where it enables learning a policy that can smoothly transition between multiple fighting styles.
This work has been accpeted for publication and is set to appear at the International Conference on Learning Representations (ICLR) 2022.
Overview
We explore the problem of multi-task reinforcement learning (MTRL), but specifically in the case where a single policy network is tasked with learning to handle multiple similar, but distinct, tasks -- making it a multi-style learning problem. The `multi-style' setting assumes RL agents operating under the same system dynamics across a selection of tasks, but where each task represents a different behavior, or `style' goal. A common approach to MTRL is to employ one-hot task encoding to delineate between tasks, but this is not always sufficient to enable successful multi-style policy-learning. We suspected that the similarity of game-play states visited between each trained style interfering with each style's value optimization. To remedy this, we developed Multi-Critic Actor Learning (MultiCriticAL), a single-actor, multi-critic framework for multi-task Actor-Critic optimization. The core idea of MultiCriticAL is to maintain separate per-style (or task) critic functions for each style being learned, thus mitigating negative interference between styles. MultiCriticAL consistently trains more performant policies, compared to its single-critic counterparts, succeeds in cases where the single-critic methods fail and achieves between significant improvement in more traditional multi-task settings involving multi-level game-play.
Results
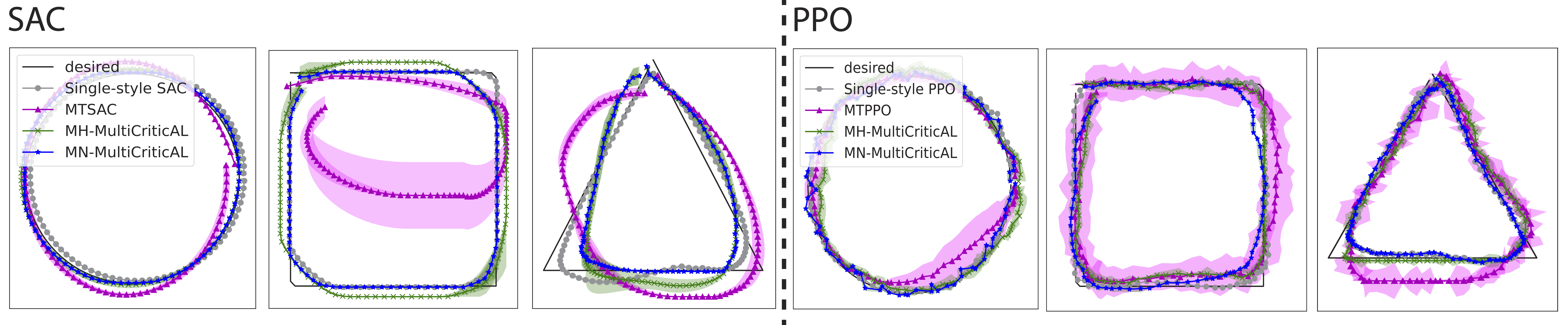
We compare policies trained with MultiCriticAL against policies trained with just the typical one-hot task/style encoding on 4 tasks.
The first is a simple shape-following task, where the RL policies are asked to do what they do best -- memorize and reproduce optimal behavior.
This is easy enough for the policies to learn when they're tasked with learning one shape at a time, but fail when asked to learn multiple shapes.
MultiCriticAL however enables significanlty improved results, as shown below.
We also test MultiCriticAL on a modified game of Pong where the paddle is allowed to rotate, thus enabling more interesting behavior.
We train policies on two styles -- Aggressive and Defesnive play.
Policies are able to learn either style independently, but the typical one-hot embeddings are not sufficient for learning both simultaneuously, with the dense Defensive play rewards dominating learned behavior, or a complete failure to learn.
MultiCriticAL on the other hand enables successful learning of both styles.
Tested on a more standard multi-task setup, on games of Sonic the Hedgehog (1 and 2), where policies are tasked with learning to control sonic on 17 levels per game, we see a continued trend of superior performance with MultiCriticAL.
Finally, tested on an experimental build of EA's UFC, we see that policies are able to learn and transition between multiple behavior styles with MultiCriticAL.
Our agent is the character with black hair, fighting against the stock AI, shown here with white hair.

Below is a video demonstrating a MultiCriticAL agent playing with different style, with the playstyle being controlled by by style sliders.
Code
For the time being, please refer to the supplementary file uploaded on OpenReview. Open-source code will be published soon.
Reference
If you find this useful in your work please consider citing:
@inproceedings{
mysore2022multicritic,
title={Multi-Critic Actor Learning: Teaching {RL} Policies to Act with Style},
author={Siddharth Mysore and George Cheng and Yunqi Zhao and Kate Saenko and Meng Wu},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=rJvY_5OzoI}
}