Language Features Matter:
Effective Language Representations for Vision-Language Tasks
Abstract
Shouldn't language and vision features be treated equally in vision-language (VL) tasks? Many VL approaches treat the language component as an afterthought, using simple language models that are either built upon fixed word embeddings trained on text-only data or are learned from scratch. We believe that language features deserve more attention, and conduct experiments which compare different word embeddings, language models, and embedding augmentation steps on five common VL tasks: image-sentence retrieval, image captioning, visual question answering, phrase grounding, and text-to-clip retrieval. Our experiments provide some striking results; an average embedding language model outperforms an LSTM on retrieval-style tasks; state-of-the-art representations such as BERT perform relatively poorly on vision-language tasks. From this comprehensive set of experiments we propose a set of best practices for incorporating the language component of VL tasks. To further elevate language features, we also show that knowledge in vision-language problems can be transferred across tasks to gain performance with multi-task training. This multi-task training is applied to a new Graph Oriented Vision-Language Embedding (GrOVLE), which we adapt from Word2Vec using WordNet and an original visual-language graph built from Visual Genome, providing a ready-to-use vision-language embedding.
Overview
Here we give an overview of our findings. For more detailed analysis and experimental results, please refer to the paper.
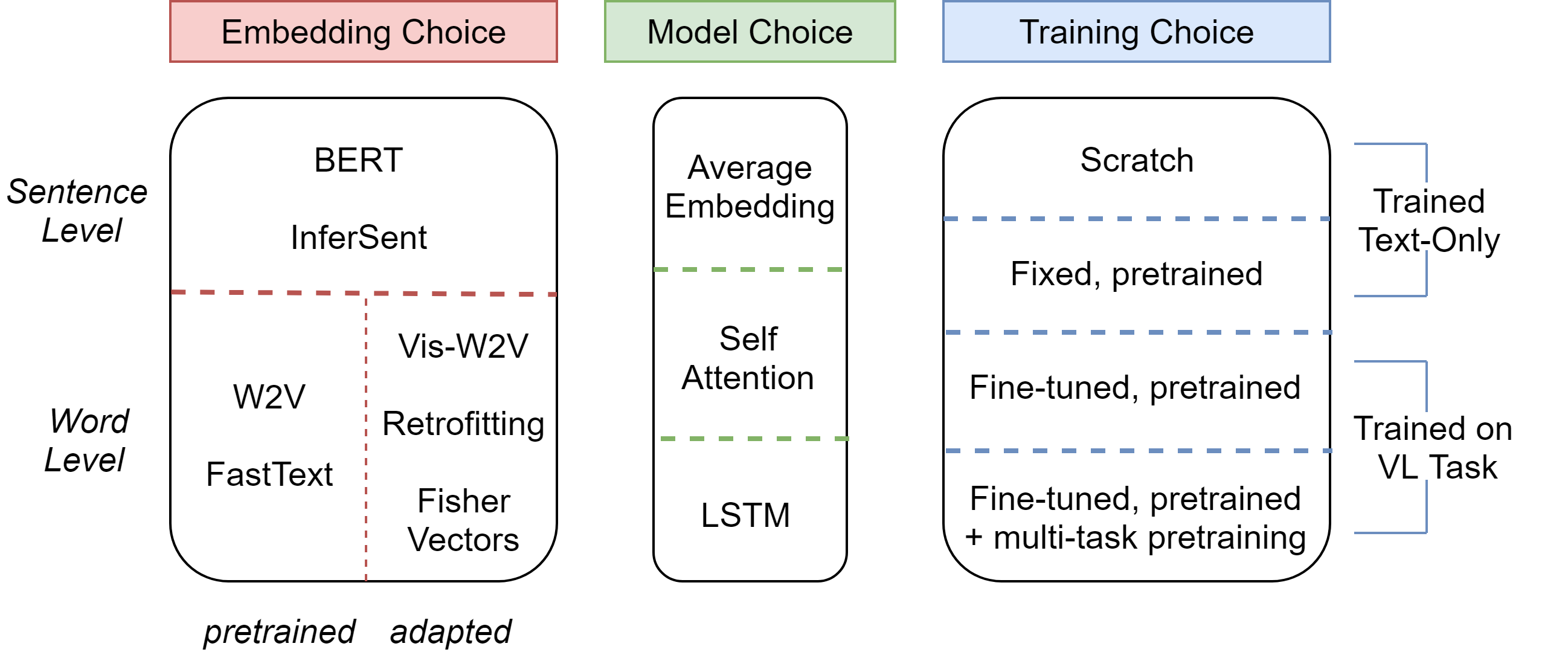
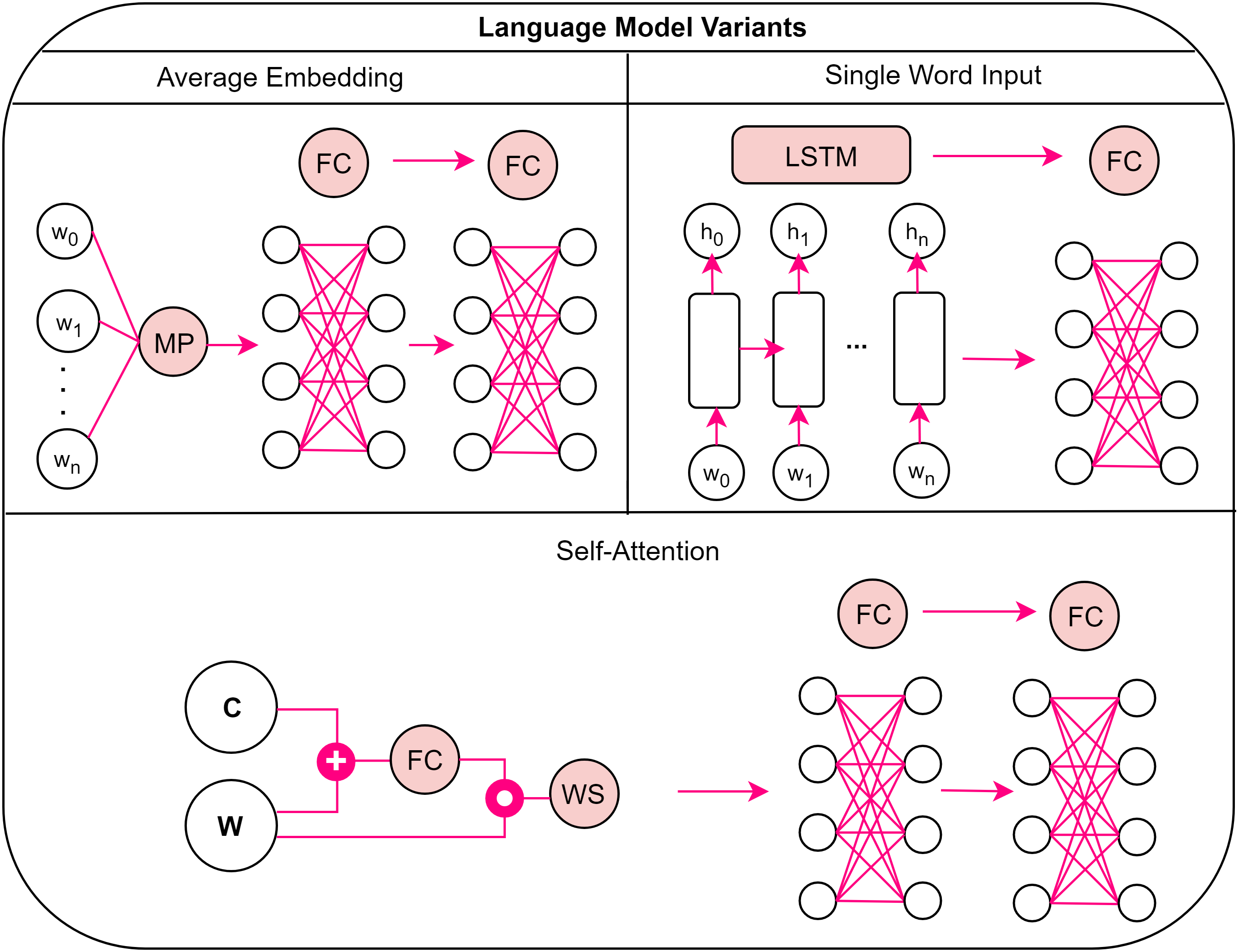
How should language features be constructed for a vision-language task? We provide a side by side comparison of how word-level and sentence-level embeddings, simple and more complex language models, and fine-tuning and post-processing vectors impact performance. The language model variants used in our experiments include: mean pooling of embeddings (MP) which is then passed to fully connected layers (FC), a LSTM fed a single embedding at a time followed by a fully connected layer, or a self-attention model which builds a weighted context sum (WS) before being passed to a pair of fully connected layers.
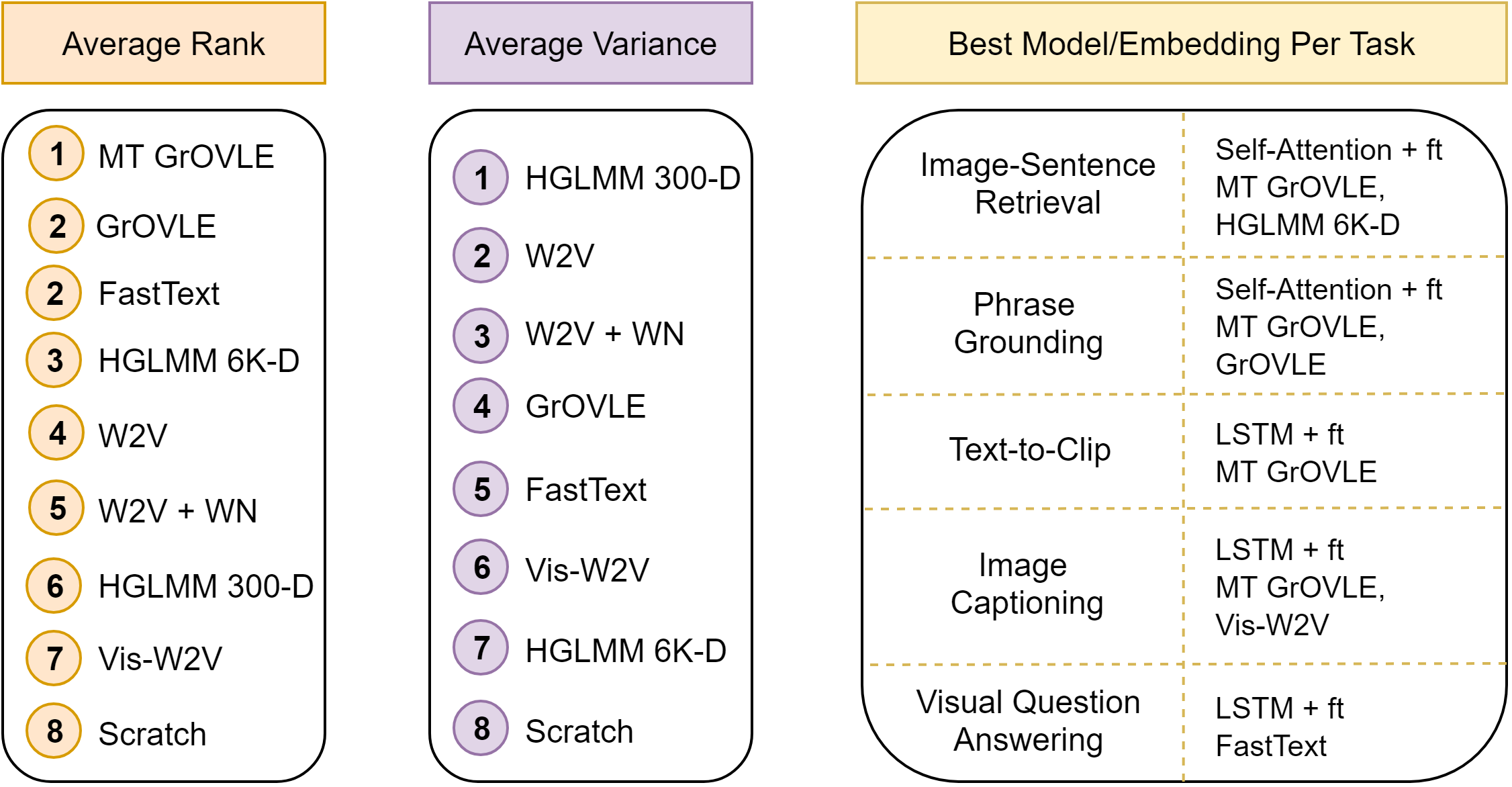
Average rank is defined using each tasks' best performing model. Variance is defined as the average difference between the best and worst performance of the fine-tuned language model options (e.g. Average Embedding + ft, Self-Attention + ft, LSTM + ft). Note that variance rank is listed from lowest to highest, e.g. from-scratch embeddings have highest variance. If the top embedding per task is a tie, both are provided in the right most column. For the tasks InferSent and BERT operate on, they would land between 7th and 8th place for average rank; average variance is N/A. Note that average variance is not provided for multi-task trained GrOVLE as it was created with the best model for each task.
Open Source Embeddings
Here we provide four embedding variants: the single task trained GrOVLE (solely adapted using knowledge bases WordNet and our Visual Genome visual-language graph), the five task multi-task trained GrOVLE, and the PCA reduced HGLMM Fisher vectors (300-D, 6K-D).
The vectors are provided in text files, numbers are space separated. Each word vector is separated with a new line character. Please note that not all vocabulary words for a given task may exist within these files. If you need words outside of these files, you can initialize them with a zero or random initialization before use during training.
GrOVLE Multi-task trained GrOVLE HGLMM 300-D HGLMM 6K-DCode
Below are code bases used to perform the experiments we present in our paper. We also link below to the retrofitting code we used to build the single task trained GrOVLE. Both the QA R-CNN model for phrase grounding and the TGN model for text-to-clip were internal implementations. QA R-CNN code will be released shortly and updated accordingly here.
- Retrofitting Word Embeddings
- Image-Sentence Retrieval
- Phrase Grounding
- Text-to-Clip
- Image Captioning
- Visual Question Answering
Reference
If you find this useful in your work please consider citing:
@inproceedings{burns2019iccv,
title={{L}anguage {F}eatures {M}atter: {E}ffective Language Representations for Vision-Language Tasks},
author={Andrea Burns and Reuben Tan and Kate Saenko and Stan Sclaroff and Bryan A. Plummer},
booktitle={The IEEE International Conference on Computer Vision (ICCV)},
year={2019}
}