R-C3D: Region Convolutional 3D Network for Temporal Activity Detection
Abstract
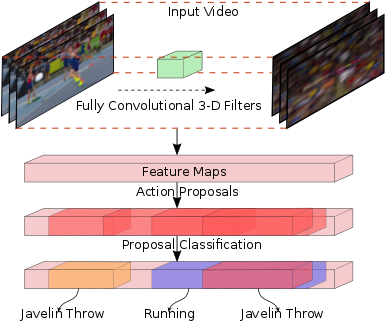
We address the problem of activity detection in continuous, untrimmed video streams. This is a difficult task that requires extracting meaningful spatio-temporal features to capture activities, accurately localizing the start and end times of each activity, and also dealing with very large data volumes. We introduce a new model, \textit{Region Convolutional 3D Network (R-C3D)}, which encodes the video streams using a three-dimensional fully convolutional network, then generates candidate temporal regions containing activities, and finally classifies selected regions into specific activities. Computation is saved due to the sharing of convolutional features between the proposal and the classification pipelines. The entire model is trained end-to-end with jointly optimized localization and classification losses. R-C3D is faster than existing methods (569 frames per second on a single Titan X Maxwell GPU) and achieves state-of-the-art results on THUMOS'14 (10% absolute improvement). We further demonstrate that our model is a general activity detection framework that does not rely on assumptions about particular dataset properties by evaluating our approach on ActivityNet and Charades.
Code
The code along with the instruction to run it can be found in https://github.com/VisionLearningGroup/R-C3D
Reference
If you find this useful in your work please consider citing:
@inproceedings{Xu2017iccv,
title = {R-C3D: Region Convolutional 3D Network for Temporal Activity Detection},
author = {Huijuan Xu and Abir Das and Kate Saenko},
booktitle = {Proceedings of the International Conference on Computer Vision (ICCV)},
year = {2017}
}