Learning to Scale Multilingual Representations for Vision-Language Tasks
Abstract
Current multilingual vision-language models either require a large number of additional parameters for each supported language, or suffer performance degradation as languages are added. In this paper, we propose a Scalable Multilingual Aligned Language Representation (SMALR) that represents many languages with few model parameters without sacrificing downstream task performance. SMALR learns a fixed size language-agnostic representation for most words in a multilingual vocabulary, keeping language-specific features for few. We use a novel masked cross-language modeling loss to align features with context from other languages. Additionally, we propose a cross-lingual consistency module that ensures predictions made for a query and its machine translation are comparable. The effectiveness of SMALR is demonstrated with ten diverse languages, over twice the number supported in vision-language tasks to date. We evaluate on multilingual image-sentence retrieval and outperform prior work by 3-4% with less than 1/5th the training parameters compared to other word embedding methods.
Overview
Here we give an overview of our findings. For more detailed analysis and experimental results, please refer to the paper.
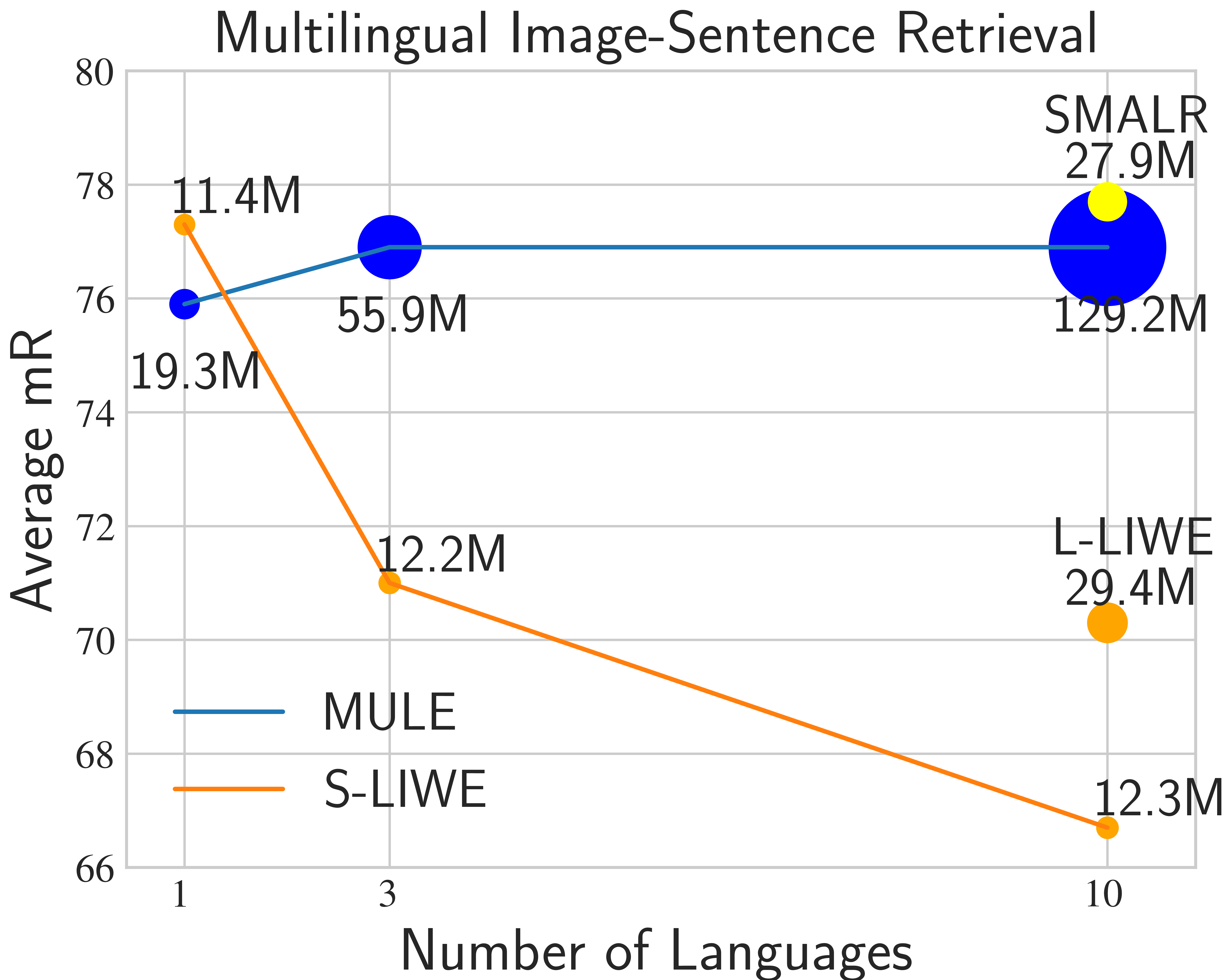
Our goal is to build scalable multilingual vision-language models that perform well in a larger multilingual setting. Prior multilingual vision-language work has evaluated at most four languages. We evaluate our work on over double that, using ten diverse languages for training and testing image-sentence retrieval: English, German, French, Czech, Chinese, Japanese, Arabic, Afrikaans, Korean, and Russian. We are able to outperform prior work with less than a fifth of the trainable parameters, balancing downstream task perform and model scalability.
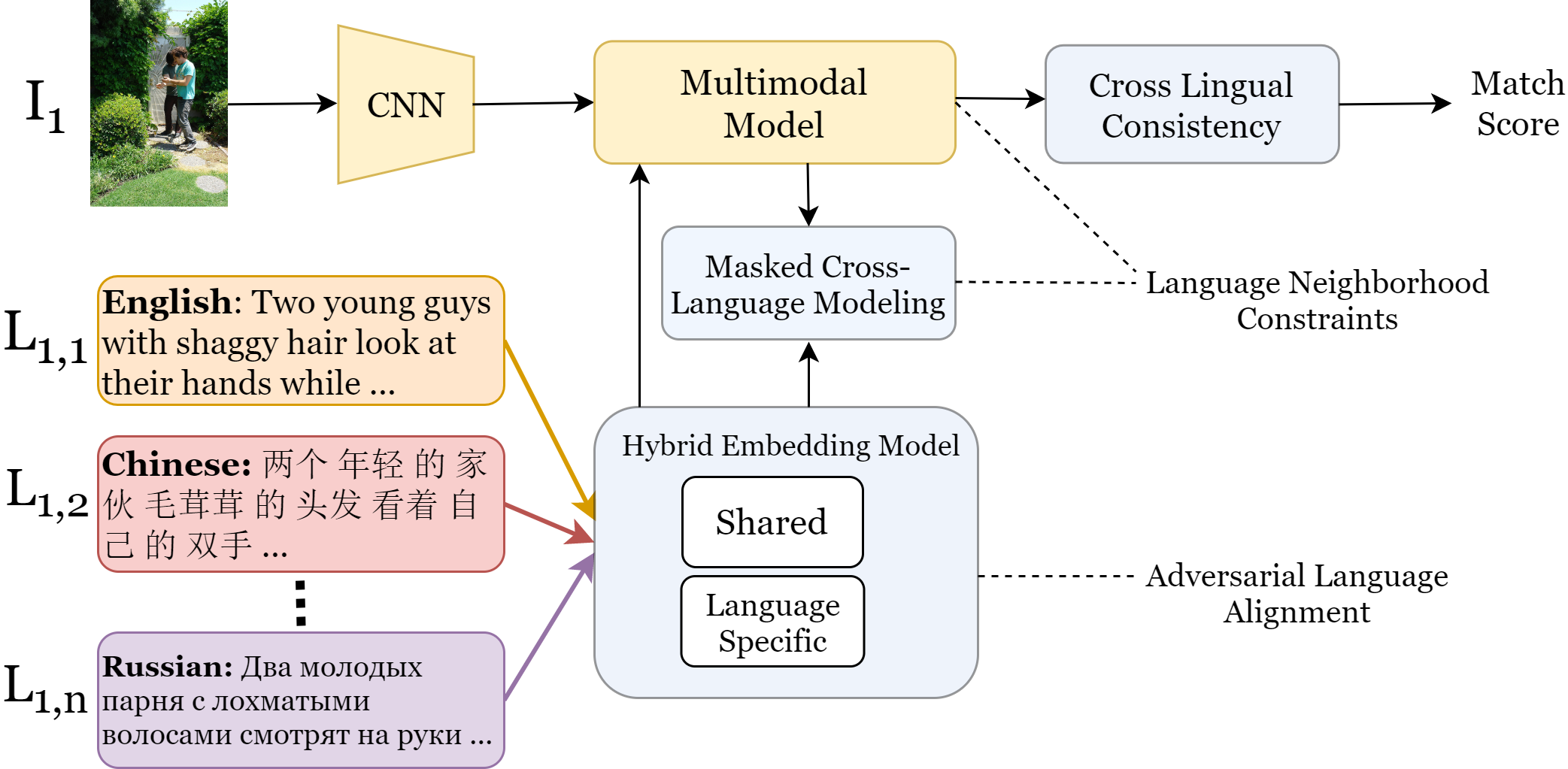
We introduce three primary contributions, highlighted in light blue, of our paper. We introduce a Hybrid Embedding model (HEM) which significantly reduces the size of our language model by reducing the number of unique language representations across our multilingual vocabulary. Next, we introduce a Masked Cross Language Model (MCLM) to better align languages amongst our diverse, challenging set of ten. We lastly introduce a test-time add on, the Cross Lingual Consistency (CLC) module which ensures consistency between a language query and its machine translations. This ultimately helps to ensemble retrieval decisions, by disambiguating subtle details from different queries and the different visual semantic information they provide.
Open Source Embeddings
COMING SOON
The vectors are provided in text files, numbers are space separated. Each word vector is separated with a new line character. Please note that not all vocabulary words for a given task may exist within these files. If you need words outside of these files, you can initialize them randomly before use during training.
SMALRCode
Code used to perform the experiments we present in our paper can be found here: COMING SOON.
Reference
If you find this useful in your work please consider citing:
@inproceedings{burns2020eccv,
title={Learning to Scale Multilingual Representations for Vision-Language Tasks},
author={Andrea Burns and Donghyun Kim and Derry Wijaya and Kate Saenko and Bryan A. Plummer},
booktitle={The European Conference on Computer Vision (ECCV)},
year={2020}
}