Syn2Real: A New Benchmark for
Synthetic-to-Real Visual Domain Adaptation
Abstract
Unsupervised transfer of object recognition models from synthetic to real data is an important problem with many potential applications. The challenge is how to "adapt" a model trained on simulated images so that it performs well on real-world data without any additional supervision. Unfortunately, current benchmarks for this problem are limited in size and task diversity. In this paper, we present a new large-scale benchmark called Syn2Real which consists of a synthetic domain rendered from 3D object models and two real-image domains containing the same object categories. We define three related tasks on this benchmark: closed-set object classification, open-set object classification, and object detection. Our evaluation of multiple state-of-the-art methods reveals a large gap in adaptation performance between the easier closed-set classification task and the more difficult open-set and detection tasks. We conclude that developing adaptation methods that work well across all three tasks presents a significant future challenge for syn2real domain transfer.
Overview
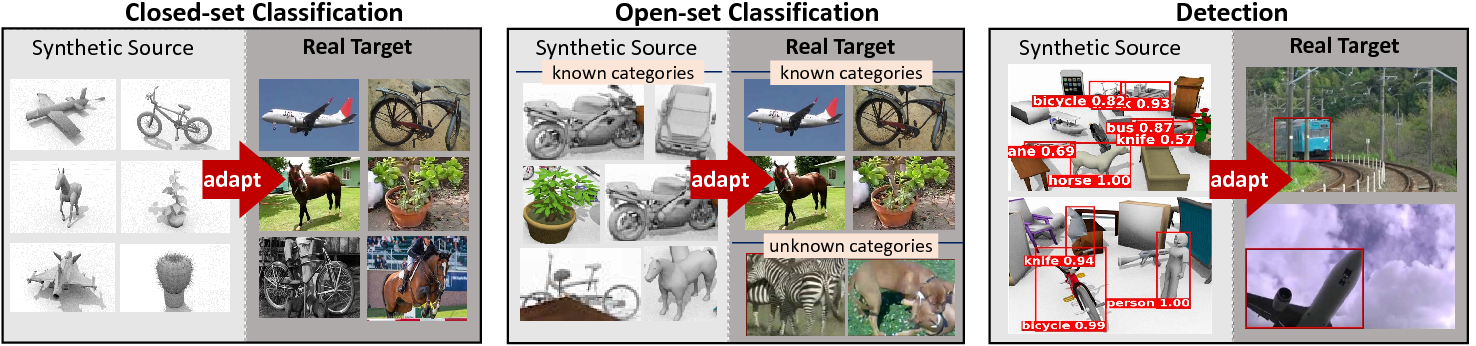
We introduce Syn2Real, a synthetic-to-real visual domain adaptation benchmark meant to encourage further development of robust domain transfer methods. The goal is to train a model on a synthetic "source" domain and then update it so that its performance improves on a real "target" domain, without using any target annotations. It includes three tasks, illustrated in figures above: the more traditional closed-set classification task with a known set of categories; the less studied open-set classification task with unknown object categories in the target domain; and the object detection task, which involves localizing instances of objects by predicting their bounding boxes and corresponding class labels.
The Syn2Real benchmark focuses on unsupervised domain adaptation (UDA) for which the target domain images are not labeled. While there may be scenarios where target labels are available (enabling \textit{supervised} domain adaptation), the purely unsupervised case is more challenging and often more realistic. For each task, we provide a synthetic source domain and two real-image target domains. Many UDA evaluation protocols do not have a validation domain and use labeled target domain data to select hyperparameters. However, assuming labeled target data goes against the UDA problem statement. For this reason, we collect two \textit{different} target domains, one for validation of hyperparameters and one for testing the models.
For the closed-set classification task, we generate the largest synthetic-to-real dataset to date with over 280K images in the combined training, validation and test sets. We use this dataset to hold a public challenge, inviting researchers from all over the world to compete on this task, and analyze the performance of the top submitted methods. We find that for this task, where the object categories are known ahead of time, recent UDA models that leverage CNN features pre-trained on ImageNet are able to achieve impressive adaptation results. This is surprising, considering that labels are only available on synthetic source images and the source and target domains are very different. We provide a detailed analysis and insight into these results.
We then push the boundaries of synthetic-to-real transfer beyond closed-set classification and design an open-set classification dataset, where the target domains contain images of additional unknown categories that were not present in the source dataset. We evaluate the state-of-the-art UDA methods available for this more difficult task, and find that there is still much room for improvement. Furthermore, we propose an even more challenging object detection benchmark that covers a much more diverse set of object categories than previous syn2real detection datasets, and show that methods that excel for adaptation of classification models completely fail when applied to recent end-to-end detection models, potentially due to very low initial performance of source models on the target data.
Examples

Data and Code
The code along with data and instructions on how to run it can be found on websites of corresponding challeges we ran: [openset and detection] [classification and segmentation]
Reference
If you find this useful in your work please consider citing:
@article{peng2017visda,
title={Visda: The visual domain adaptation challenge},
author={Peng, Xingchao and Usman, Ben and Kaushik, Neela and Hoffman, Judy and Wang, Dequan and Saenko, Kate},
journal={arXiv preprint arXiv:1710.06924},
year={2017}
}
@article{Peng2018Syn2RealAN,
title={Syn2Real: A New Benchmark forSynthetic-to-Real Visual Domain Adaptation},
author={Xingchao Peng and Ben Usman and Kuniaki Saito and Neela Kaushik and Judy Hoffman and Kate Saenko},
journal={CoRR},
year={2018},
volume={abs/1806.09755}
}