
Visual Domain Adaptation Challenge
(VisDA-2022)
Workshop
The online NeurIPS'22 workshop for VisDA-2022 was on Thursday, December 8th 2022 at 21:00 UTC (16:00 EST/15:00 CST). Find the workshop recording here. Click here to see a quick overview of the competition.
| # | Team Name | Affiliation | mIoU / Pixel Acc (%) |
|---|---|---|---|
| 1 | SI Analytics [code] | SI Analytics, Hanbat National University Daehan Kim, Minseok Seo, YoungJin Jeon, Dong-Geol Choi | 59.42 / 93.18 |
| 2 | Pros [code] | Tel-Aviv University Shahaf Ettedgui, Shady Abu-Hussein, Raja Giryes | 55.46 / 92.59 |
| 3 | BIT-DA [code] | Beijing Institute of Technology Binhui Xie, Mingjia Li, Qingju Guo, Shuang Li | 54.38 / 91.80 |
| Time (CST) | Title | Presenter(s) |
|---|---|---|
| 3:00 p.m. - 3:15 p.m. | Challenge Introduction (Talk) | Dina Bashkirova |
| 3:15 p.m. - 4:00 p.m. | Presentations from Winners (Presentations + Q&A) | Binhui Xie · Shahaf Ettedgui · Daehan Kim |
| 4:00 p.m. - 4:20 p.m. | Subhransu Maji: Learning to Track Birds with Weather RADARs (Talk) | Subhransu Maji |
| 4:20 p.m. - 4:40 p.m. | Colorado Reed: From AI for Science to Science for AI. A tale of ice, fire, and domain adaptation (Talk) | Colorado Reed |
| 4:40 p.m. - 5:00 p.m. | Amanda Marrs: Applying AI and Computer Vision to Modernize Recycling and Increase Landfill Diversion (Talk) | Amanda Marrs |
| 5:00 p.m. - 5:20 p.m. | Ian Goodine, Ethan Walko: Decentralized Waste Sorting (Talk) | Ian Goodine |
| 5:20 p.m. - 5:40 p.m. | Sujit Sanjeev: Introduction to CircularNet (Talk) | Sujit Sanjeev |
| 5:40 p.m. - 6:00 p.m. | Final Q&A and Discussion Session (Discussion Panel) | All |
Overview
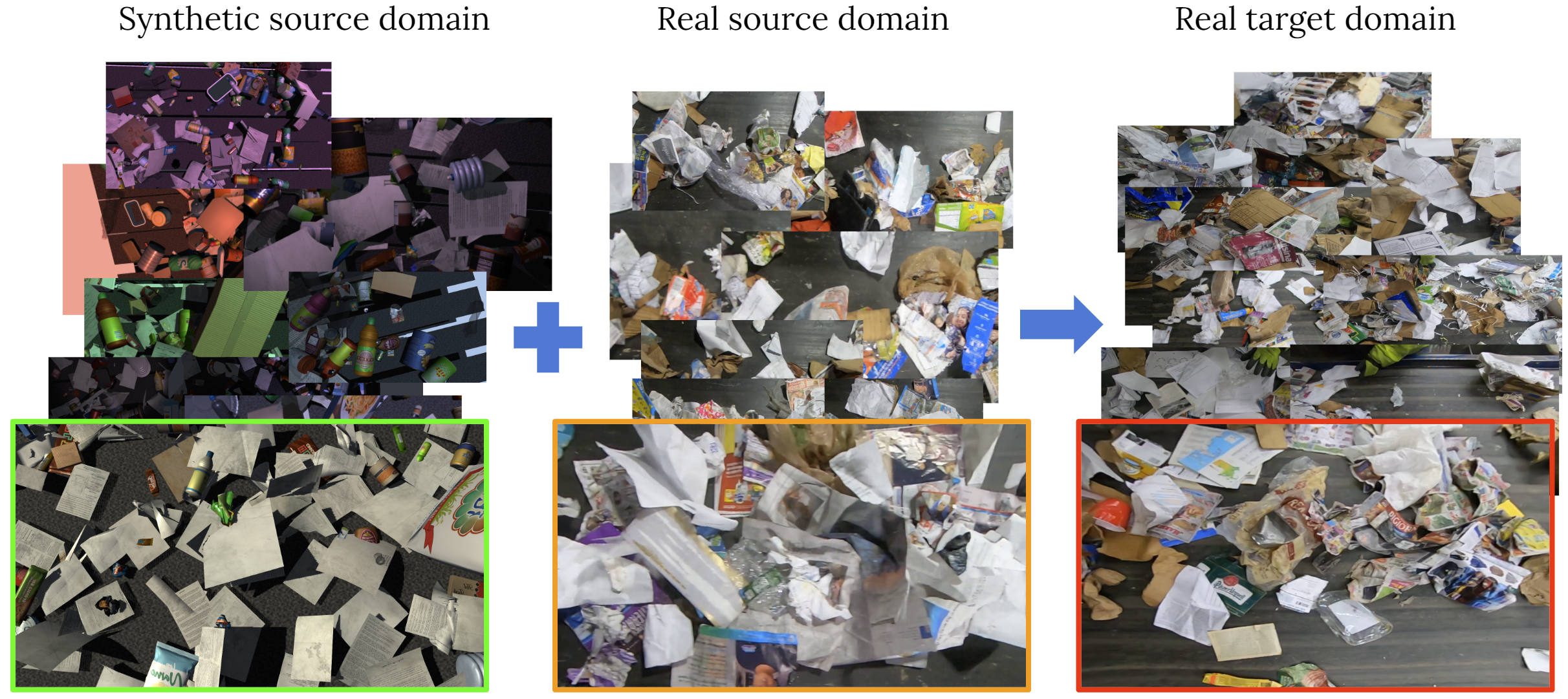
Welcome to the Visual Domain Adaptation 2022 Challenge! This year, our challenge brings domain adaptation closer to real-world applications, as we propose the task of semantic segmentation for industrial waste sorting. It is the 6th edition of the challenge and we look forward to participation from a large and growing NeurIPS community with a breadth of backgrounds.
In industrial waste sorting, it is impossible to collect a gold standard dataset that fully represents the task, since the visual appearance of the waste stream as well as its content changes overtime and depends on the specific location, season, machinery in use, and many other factors, all of which introduce a natural domain shift between any source/training and target distributions. Therefore, this year, we challenge the computer vision community to come up with effective solutions for the domain adaptation problem in this real-world application. Our challenge consists of a large-scale synthetic SynthWaste dataset as well as the real ZeroWaste dataset as source domains, and ZeroWasteV2, the real dataset collected at a different location and season, as a target domain. Additionally, we provide SynthWaste-aug, a version of SynthWaste augmented with instance-level style transfer to further increase the diversity of the synthetic dataset. The goal of this challenge is to answer the question: can synthetic data improve performance on this task and help adapt to changing data distributions? We invite the teams to help answer this question and facilitate research aimed at solving the automated waste sorting problem.
Announcements
Prizes
The top three teams will receive pre-paid VISA gift cards: $2000 for the 1st place, $500 for 2nd and 3rd.
Rules
- Participants from both academic and industrial institutions are welcome to participate in our challenge. The participating teams agree to publish the full code that allows reproducibility in case of a victory (top 3 solutions). The list of team members must be provided during registration, and cannot be changed throughout the competition. Each individual can only participate in one team and should provide the institution / corporate email and a phone number at registration.
- Teams may use any publicly available and appropriately licensed data to train their models in addition to the ones provided by the organizers. Supervised training on the validation set of the target domain is not allowed in this competition.
- Models can be adapted using the unsupervised dataset from the target domain without access to the labels. For example, solutions that involve supervised training on the validation set or manual labeling of the target domain will be disqualified.
- The choice of segmentation backbone greatly affects the domain adaptation results. To allow fair comparison, participants will be asked to submit the following results: source-only predictions of a backbone model trained only on data from the source domains, as well as the domain adaptation results of the model trained on source and unlabeled target data.
- The winning solutions will be determined based on the test mIoU of the adapted model on target data. In an unlikely event of a tie, mean pixel accuracy will be used to break the tie.
- To encourage fair competition regardless of affiliation and compute capabilities, we limit the overall model size to 300 million parameters. If multiple distinct models are used, the total number of parameters will be counted according to the number of forward passes of the same input batch. For example, if the same input example is passed to the model that has 150 millions of parameters twice, it will count as 300 millions of parameters in total. Note that for a segmentation model, we shall count this per-pixel, meaning, the number of parameters is the maximum value of forward passes times number of model parameters for any given pixel. Hence, if you choose to do inference over multiple non-overlapping windows for a single image using a model with 150 million parameters, although you may run a forward pass multiple times, any individual pixel of the image is processed by a model of at most 150 million parameters, which keeps it under the limit of 300 million.
- Reproducibility is the responsibility of the winning teams. Top-3 winning solutions must submit the full code along with a complete list of instructions / script on how to reproduce their results, ideally with the exact random seeds used to get the best result. If the organizing committee determines that the submitted code runs with errors or does not yield results comparable to those in the final leaderboard and the team is not willing to cooperate, it will be disqualified, and the winning place will go to the next team in the leaderboard.
- Energy efficiency: Teams must report the total training time of the submitted model which should be reasonable (which we define as not exceeding 100 GPU days of V100 (16GB version) but contact us if unsure). Energy efficient solutions will be highlighted even if they do not finish in the top three.
- In Phase 2 of the challenge, each team is allowed a maximum of 5 submissions.
Sponsors
