Honey, I Shrunk The Actor: A Case Study on Preserving Performance with Smaller Actors in Actor-Critic RL
Abstract
Actors and critics in actor-critic reinforcement learning algorithms are functionally separate, yet they often use the same network architectures. This case study explores the performance impact of network sizes when considering actor and critic architectures independently. By relaxing the assumption of architectural symmetry, it is often possible for smaller actors to achieve comparable policy performance to their symmetric counterparts. Our experiments show up to 99% reduction in the number of network weights with an average reduction of 77% over multiple actor-critic algorithms on 9 independent tasks. Given that reducing actor complexity results in a direct reduction of run-time inference cost, we believe configurations of actors and critics are aspects of actor-critic design that deserve to be considered independently, particularly in resource-constrained applications or when deploying multiple actors simultaneously.
Overview
RL-based algorithms can learn interesting control policies for a wide array of tasks but there has been limited prior exploration into how well optimized the network architectures are, for the various problems explored in contemporary RL. While investigating the behavior of Actor-Critic RL algorithms, we were curious about just how small actors could get before they fail to learn. To begin, we wanted to see if RL agents would be able to learn to solve a simple problem, for which a linear 1-neuron policy would suffice (more details in the paper) We discovered that, if one were to restrict architectural exploration with an assumption of symmetry in the actor and critic architectures, this simple problem could not be solved, however, by breaking the symmetry and using a larger critic, the problem becomes solvable. This led us to hypothesize that it was likely the critic that required more representational power in learning to understand the environments, while actors could perhaps manage with smaller networks.
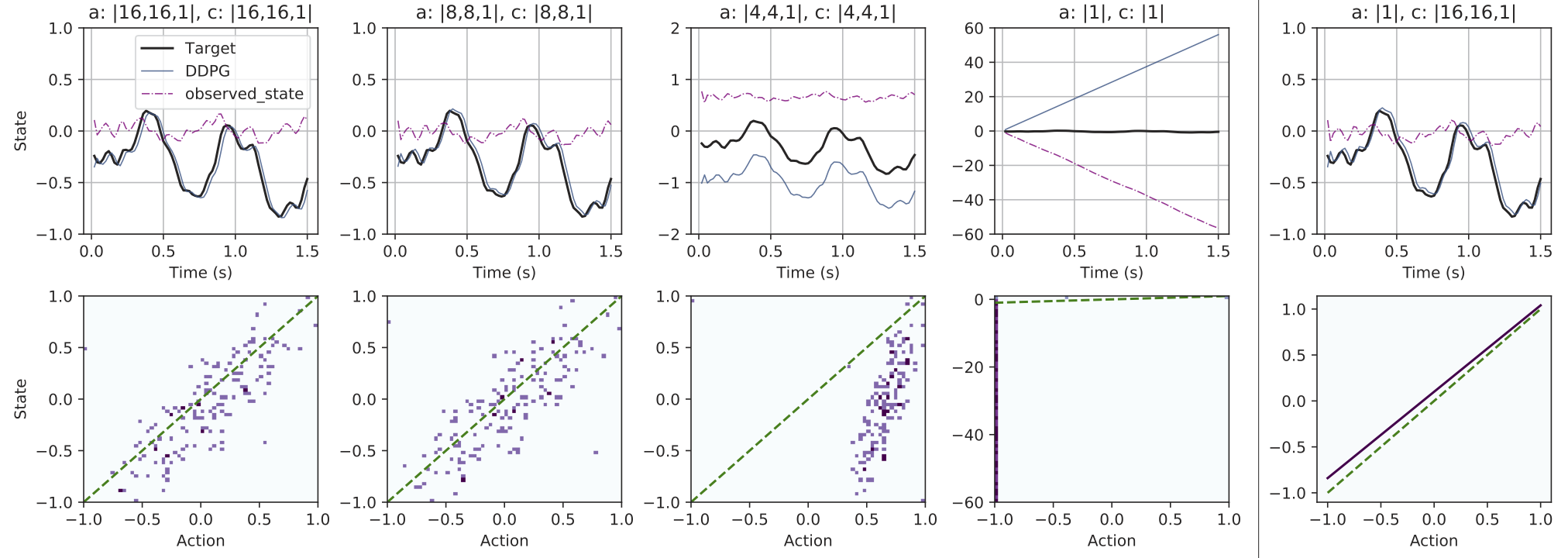
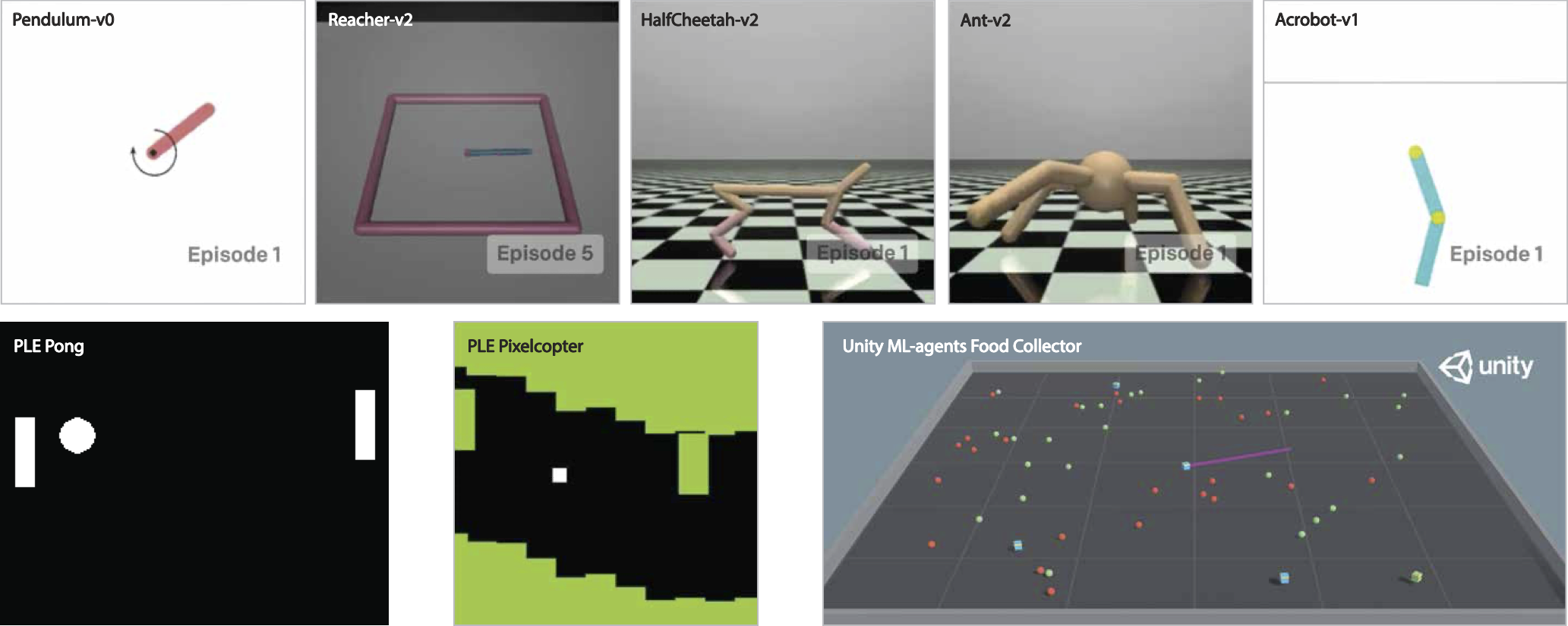
To test this hypothesis, we ran over 1k experiments to determine if 4 commonly used actor-critic algorithms (DDPG, TD3, PPO, SAC) would allow for smaller actors by breaking architectural symmetry with the critics. We tested these algorithms on a number of OpenAI Gym benchmarks as well as games from the PyGame Learning Environment and Unity's ML-Agents API.
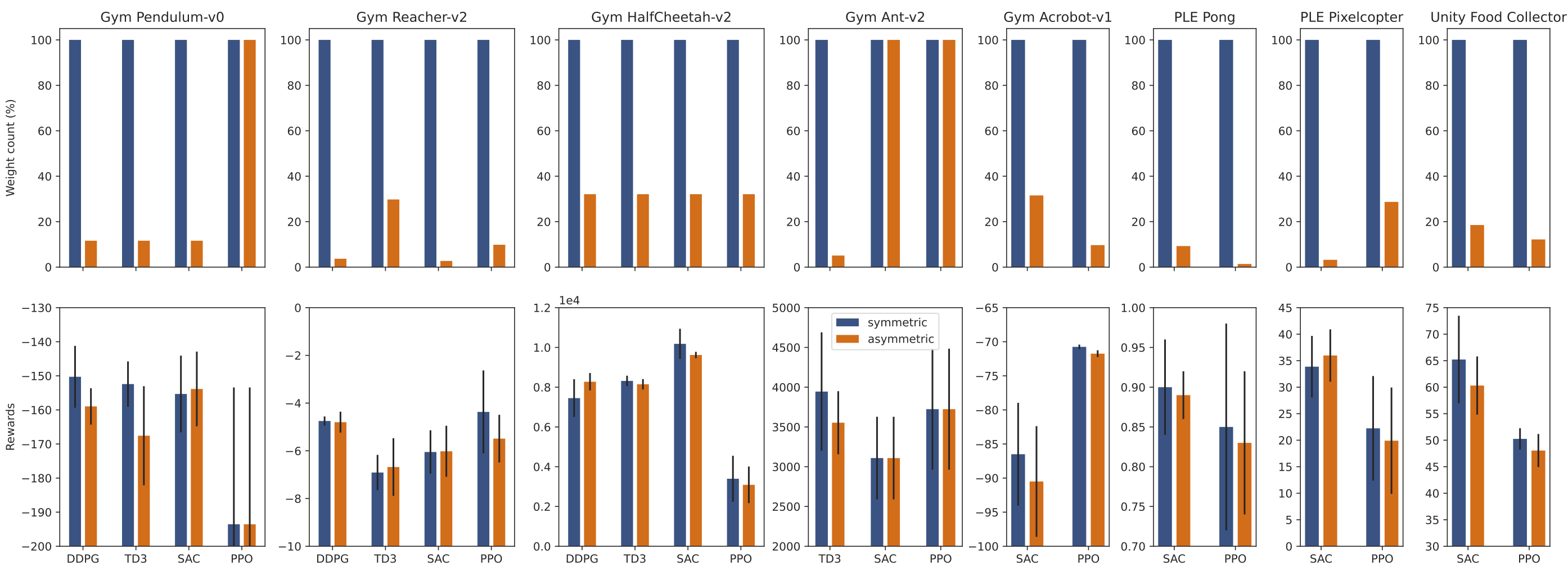
Our results showed that it was indeed often possible to train smaller actors while maintaining performance parity. Over the 8 tasks tested, we were able to achieve an average actor-network size reduction of 77% with up to 98% on some tasks.
Code
For the time being, a zipped copy of the code as used for the benchmarks and toy problem is available via the source below.
Reference
If you find this useful in your work please consider citing:
@inproceedings{mysore2021littleActor,
title={Honey, I Shrunk The Actor: A Case Study on Preserving Performance with Smaller Actors in Actor-Critic RL},
author={Siddharth Mysore and Bassel Mabsout and Renato Mancuso and Kate Saenko},
journal={IEEE Conference on Games},
year={2021},
}